Reasoning Models
Reasoning models are large language models specifically designed or trained to perform explicit multi-step logical reasoning before generating a final answer. Rather than producing immediate responses, they "think" through problems using internal chain-of-thought processes—often visibly showing their work.
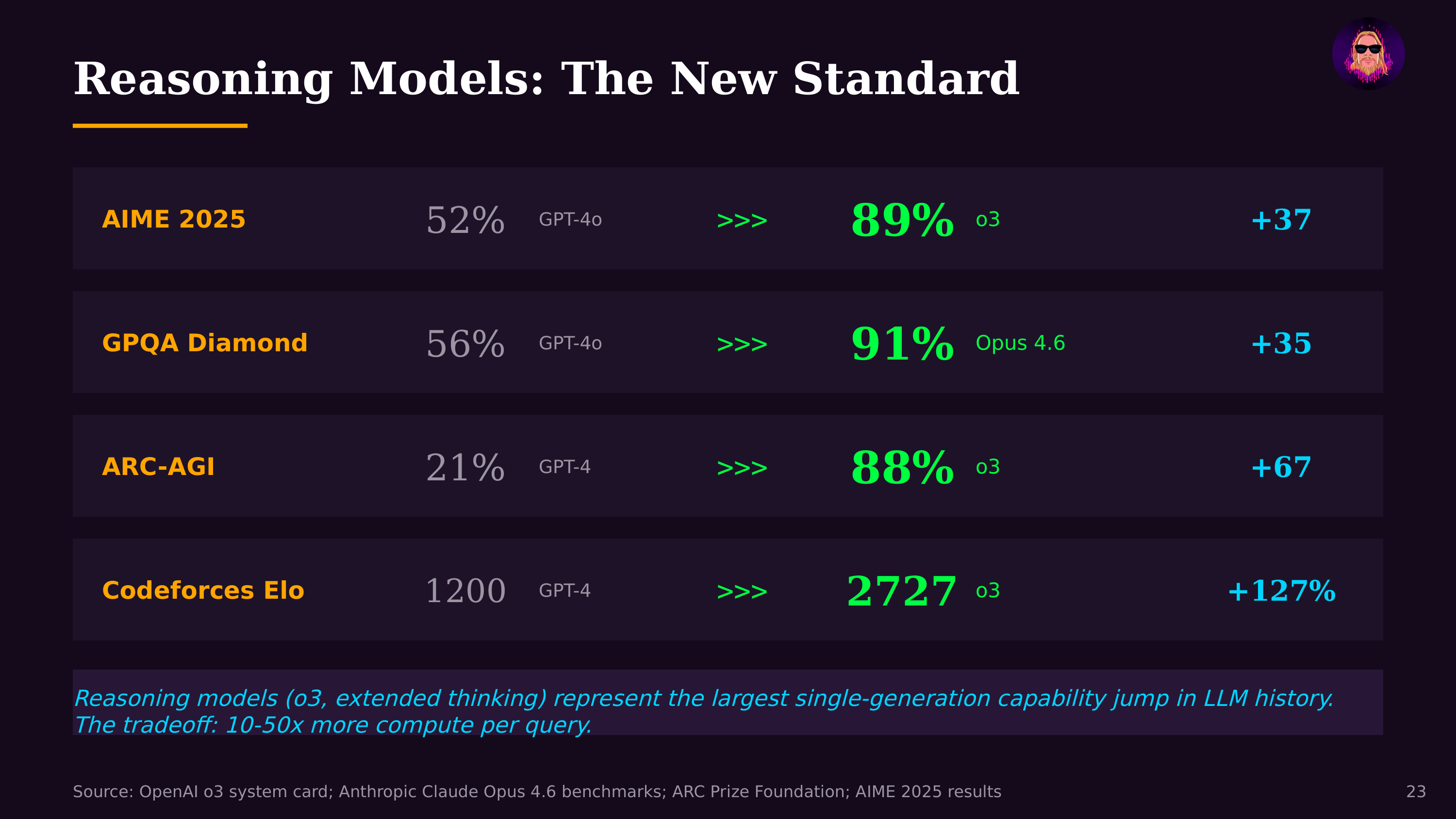
The category emerged as a distinct paradigm with OpenAI's o1 (September 2024) and o3 models, Anthropic's Claude with extended thinking, Google's Gemini 2.0 Flash Thinking, and DeepSeek-R1. These systems allocate additional compute at inference time to decompose complex problems into steps, verify intermediate results, and reconsider approaches when they hit dead ends. The tradeoff is latency and cost for accuracy: reasoning models take longer and consume more tokens but achieve dramatically better performance on math, coding, science, and logic tasks.
The training techniques behind reasoning models represent a significant advance. Reinforcement fine-tuning with verifiable rewards teaches models to reason by rewarding correct final answers on problems with objectively checkable solutions. DeepSeek-R1 demonstrated that pure reinforcement learning—without supervised chain-of-thought examples—could produce emergent reasoning behavior, a result that surprised much of the field.
For AI agents, reasoning capability is what enables complex autonomous behavior. An agent that can reason through multi-step plans, debug its own errors, and verify its work can operate on the 14.5-hour autonomous task horizons now being measured. The combination of reasoning models with tool use and agentic engineering frameworks is what makes the Creator Era possible—these aren't just smarter chatbots, they're systems that can think through and execute complex projects.